Понимание и визуализация
Понимание и визуализация
(эта страница в настоящее время находится в черновом варианте)
В литературе было разработано несколько подходов к пониманию и визуализации сверточных сетей, отчасти в ответ на распространенную критику о том, что изученные признаки в нейронной сети не поддаются интерпретации. В этом разделе мы кратко рассмотрим некоторые из этих подходов и связанную с ними работу.
Визуализация активаций и веса первого слоя
Активации слоев. Наиболее простой метод визуализации заключается в том, чтобы показать активации сети во время прямого прохода. В сетях ReLU активации обычно выглядят относительно неровными и плотными, но по мере обучения активации обычно становятся более редкими и локализованными. Одна из опасных ловушек, которую можно легко заметить с помощью этой визуализации, заключается в том, что некоторые карты активации могут быть равны нулю для множества различных входных данных, что может указывать на мертвые фильтры и может быть симптомом высокой скорости обучения.


Типичные активации на первом слое CONV (сверху) и на 5-м слое CONV (снизу) обученного AlexNet смотрят на изображение кошки. В каждом боксе отображается карта активации, соответствующая какому-либо фильтру. Обратите внимание, что активации редкие (большинство значений равны нулю, на этой визуализации показаны черным цветом) и в основном локальные.
Фильтры Conv/FC. Вторая распространенная стратегия заключается в визуализации весов. Обычно они наиболее интерпретируемы на первом слое CONV, который смотрит непосредственно на необработанные пиксельные данные, но также можно показать веса фильтров в более глубоких слоях сети. Весовые коэффициенты полезны для визуализации, потому что хорошо обученные сети обычно отображают красивые и плавные фильтры без каких-либо зашумленных узоров. Зашумленные паттерны могут быть индикатором сети, которая не обучалась достаточно долго, или, возможно, очень низкой интенсивности регуляризации, которая могла привести к переобучению.


Типичные фильтры на первом слое CONV (сверху) и на 2-м слое CONV (снизу) обученного AlexNet. Обратите внимание, что веса первого слоя очень красивые и гладкие, что указывает на хорошо сходящуюся сеть. Функции цвета/оттенков серого сгруппированы, потому что AlexNet содержит два отдельных потока обработки, и очевидным следствием такой архитектуры является то, что один поток развивает высокочастотные элементы оттенков серого, а другой — низкочастотные цветовые функции. Веса 2-го слоя CONV не так легко интерпретируемы, но очевидно, что они все еще гладкие, хорошо сформированные и лишены зашумленных узоров.
Получение изображений, которые максимально активируют нейрон
Еще один метод визуализации заключается в том, чтобы взять большой набор изображений, пропустить их через сеть и отслеживать, какие изображения максимально активируют тот или иной нейрон. Затем мы можем визуализировать изображения, чтобы понять, что нейрон ищет в своем рецептивном поле. Одна из таких визуализаций (среди прочих) показана в статье Богатые иерархии функций для точного обнаружения объектов и семантической сегментации Росса Гиршика и др.:
Максимально активизирующие изображения для некоторых нейронов POOL5 (5-й слой пула) AlexNet. Значения активации и рецептивное поле конкретного нейрона показаны белым цветом. (В частности, обратите внимание, что нейроны POOL5 являются функцией относительно большой части входного изображения!) Можно видеть, что некоторые нейроны реагируют на верхнюю часть тела, текст или зеркальные блики.
Одна из проблем с этим подходом заключается в том, что нейроны ReLU не обязательно имеют какое-либо семантическое значение сами по себе. Скорее, более уместно думать о множественных нейронах ReLU как о базисных векторах некоторого пространства, представленного в виде участков изображения. Другими словами, визуализация показывает участки на краю облака представлений, вдоль (произвольных) осей, которые соответствуют весам фильтра. Это также можно увидеть по тому факту, что нейроны в ConvNet работают линейно над входным пространством, поэтому любое произвольное вращение этого пространства является запретным. Этот момент был далее аргументирован в книге Сегеди и др. «Интригующие свойства нейронных сетей», где они выполняют аналогичную визуализацию вдоль произвольных направлений в пространстве представления.
Встраивание кодов с помощью t-SNE
ConvNet можно интерпретировать как постепенное преобразование изображений в представление, в котором классы разделяются линейным классификатором. Мы можем получить приблизительное представление о топологии этого пространства, встроив изображения в два измерения таким образом, чтобы их низкоразмерное представление имело примерно равные расстояния, чем их высокомерное представление. Существует множество методов вложения, которые были разработаны с помощью интуиции вложения векторов высокой размерности в пространство низкой размерности с сохранением парных расстояний точек. Среди них t-SNE является одним из самых известных методов, который неизменно дает визуально приятные результаты.
Чтобы произвести встраивание, мы можем взять набор изображений и использовать ConvNet для извлечения кодов CNN (например, в AlexNet 4096-мерный вектор прямо перед классификатором, и, что особенно важно, включая нелинейность ReLU). Затем мы можем подключить их к t-SNE и получить двумерный вектор для каждого изображения. Соответствующие изображения могут быть визуализированы в виде сетки:

Встраивание набора изображений в t-SNE на основе их кодов CNN. Изображения, которые находятся рядом друг с другом, также близки в пространстве репрезентации CNN, что подразумевает, что CNN «видит» их как очень похожие. Обратите внимание, что сходства чаще всего основаны на классах и семантике, а не на пикселях и цветах. Для получения более подробной информации о том, как была создана эта визуализация, связанный код, а также другие связанные визуализации в разных масштабах см. Визуализация кодов CNN в t-SNE.
Окклюзия частей изображения
Предположим, что ConvNet классифицирует изображение как собаку. Как мы можем быть уверены, что он на самом деле улавливает собаку на изображении, а не какие-то контекстуальные подсказки на фоне или какой-то другой объект? Одним из способов исследования того, из какой части изображения исходит предсказание классификации, является построение графика вероятности интересующего класса (например, класса собаки) в зависимости от положения объекта-окклюдера. То есть, мы перебираем области изображения, устанавливаем участок изображения равным нулю и смотрим на вероятность класса. Мы можем визуализировать вероятность в виде двумерной тепловой карты. Этот подход был использован в книге Мэтью Цайлера «Визуализация и понимание сверточных сетей»:
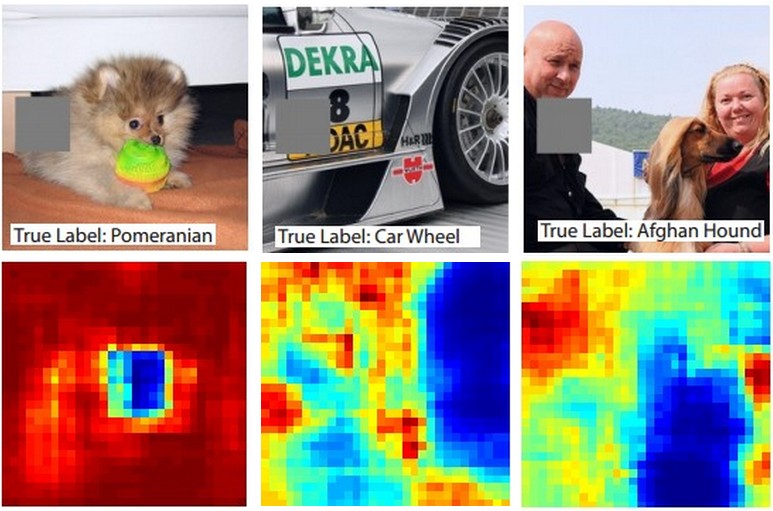
Три входных изображения (вверху). Обратите внимание, что окклюдерная область показана серым цветом. Когда мы проводим окклюдером по изображению, мы записываем вероятность правильного класса, а затем визуализируем его в виде тепловой карты (показанной под каждым изображением). Например, на крайнем левом изображении мы видим, что вероятность померанского шпица резко падает, когда окклюдер закрывает морду собаки, что дает нам некоторую степень уверенности в том, что морда собаки в первую очередь ответственна за высокий балл классификации. И наоборот, обнуление других частей изображения имеет относительно незначительное влияние.
Визуализация градиента данных и его друзей
Градиент данных.|
Глубоко внутри сверточных сетей: визуализация моделей классификации изображений и карт заметности
DeconvNet.
Визуализация и понимание сверточных сетей
Управляемое обратное распространение.
Стремление к простоте: Всесвёрточная сеть
Восстановление оригинальных изображений на основе кодов CNN
Понимание глубоких представлений изображений путем их инвертирования
Какой объем пространственной информации сохраняется?
Учатся ли ConvNet переписываться? (Вкратце: да)
Производительность построения графиков в зависимости от атрибутов изображения
ImageNet Wide Scale Visual Recognition Challenge
Обман ConvNet
Объяснение и использование состязательных примеров