Python numpy (с Jupyter и Colab)
Блокнот Colab
Этот урок был первоначально предоставлен Джастином Джонсоном.
Мы будем использовать язык программирования python для всех заданий этого курса.
Python сам по себе является отличным языком программирования общего назначения, но с помощью нескольких популярных библиотек (numpy, scipy, matplotlib) он становится мощной средой для научных вычислений.
Мы ожидаем, что многие из вас имеют некоторый опыт работы с python и numpy.
Если нет, то этот раздел послужит кратким ускоренным курсом по обоим направлениям языка программирования python и его использованию для научных исследований и вычислений.
Мы также познакомимся с Jupyter-notebooks, которые являются очень удобным способом работы с кодом на python.
Ссылки на полезные ресурсы:
- Stepic курс по python
- NumPy для пользователей Matlab,
- python для пользователей R ,
- python для пользователей SAS.
Содержание
- Блокноты Jupyter и Colab
- Питон
- Версии python
- Основные типы данных
- Контейнеры
- Списках
- Словари
- Множество
- Кортежи
- Функции
- Классы
- Numpy
- Массивы
- Индексация массивов
- Типы данных
- Математические операции с массивами
- Broadcasting
- Документация Numpy
- SciPy
- Операции с изображениями
- Файлы MATLAB
- Расстояние между точками
- Matplotlib
- Постоение кривой
- Побочные сюжеты
- Изображения
Блокноты Jupyter и Colab
Прежде чем мы углубимся в python, мы хотели бы кратко поговорить о блокнотах.
Блокнот Jupyter позволяет писать и выполнять код python локально в вашем веб-браузере.
Jupyter notebooks yпрощает работу с кодом и выполняет его по блокам.
По этой причине он широко используется в научных вычислениях.
Colab, с другой стороны, является разновидностью Google-блокнота Jupyter, который особенно подходит для машинных алгоритмов обучения и анализа данных, которые сохраняют функционал в облаке.
Colab — это, по сути, Jupyter notebook на стероидах: он бесплатный, не требует настройки, поставляется с предустановленными пакетами, им легко поделиться со всем миром.
В нем присутствуют преимущества бесплатного доступа к аппаратным ускорителям, таким как графические процессоры и TPU (с некоторыми оговорками).
Запустите Tutorial в Colab (рекомендуется). Если вы хотите выполнить это руководство полностью в Colab, нажмите на значок Open in Colab в самом верху этой страницы.
Запустите Tutorial в блокноте Jupyter. Если вы хотите запустить блокнот локально с помощью Jupyter, убедитесь, что ваша виртуальная среда установлена правильно (в соответствии с инструкциями по настройке), активируйте ее, а затем запустите pip install notebook для установки блокнота Jupyter. Затем откройте блокнот и загрузите его в каталог по вашему выбору, щелкнув правой кнопкой мыши по странице и выбрав Save Page As. Затем cd в этот каталог и запустите jupyter notebook.
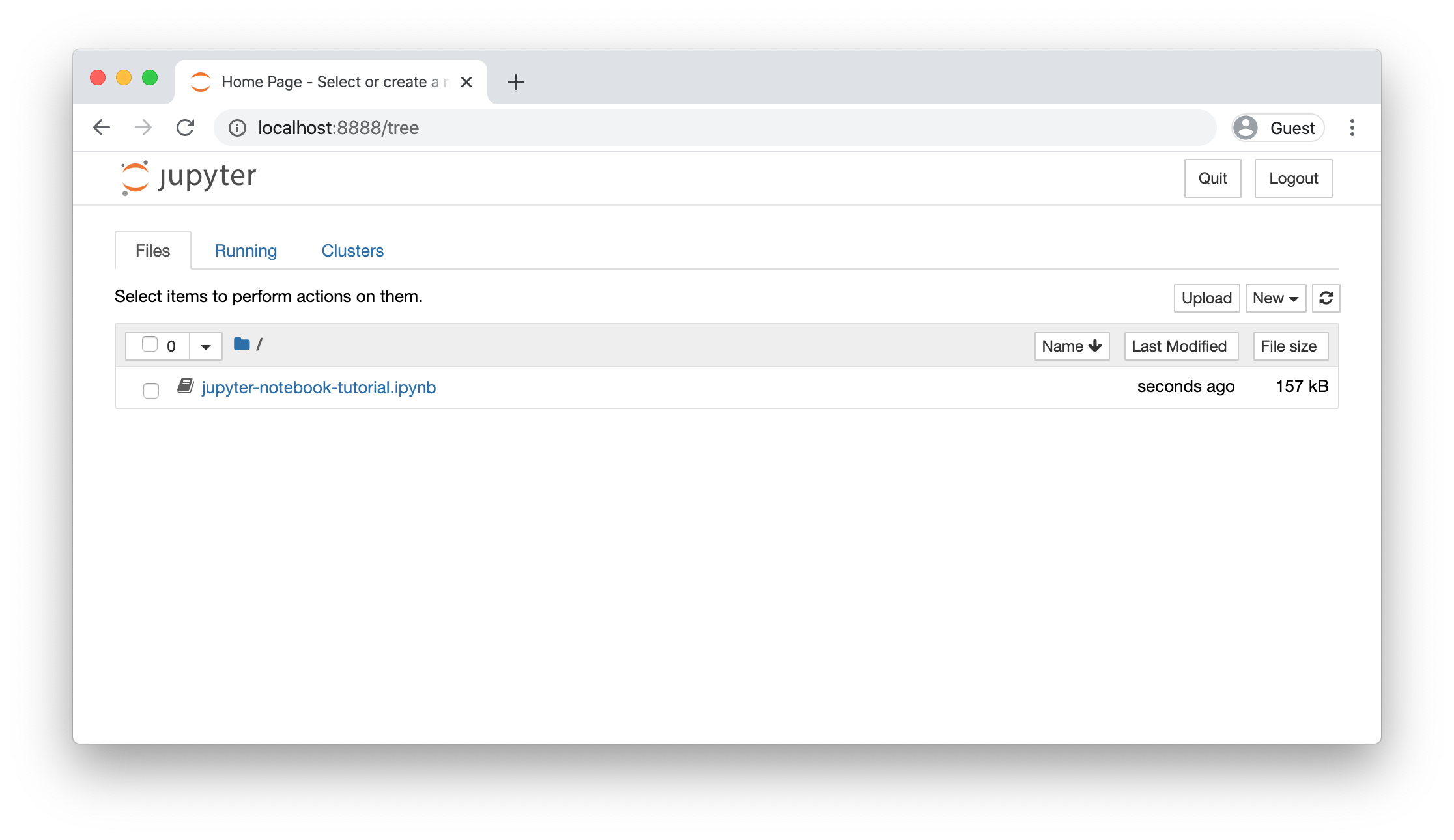
Это должно автоматически запустить сервер блокнотов по адресу http://localhost:8888. Если все работало правильно, вы должны увидеть такой экран, показывающий все доступные записные книжки в текущем каталоге. Нажмите jupyter-notebook-tutorial.ipynb и следуйте инструкциям в блокноте. В противном случае вы можете продолжить чтение туториала с фрагментами кода ниже.
Python
Python — это высокоуровневый, динамически типизированный мультипарадигмальный язык программирования. О коде на python часто говорят, что он похож на псевдокод, поскольку он позволяет вам выражать очень мощные идеи в очень немногих строках кода, оставаясь при этом очень удобочитаемый. В качестве примера приведем реализацию алгоритма классической быстрой сортировки на python:
def quicksort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quicksort(left) + middle + quicksort(right)
print(quicksort([3,6,8,10,1,2,1]))
# Prints "[1, 1, 2, 3, 6, 8, 10]"
Версии python
С 1 января 2020 года python официально прекратил поддержку второй версии.
Поэтому во всех примерах код написан на python 3.7. Убедитесь, что вы правильно установили виртуальную среду, прежде чем продолжить работу с этим руководством. Вы можете проверить свою версию в командной строке после активации среды, запустив команду: python --version
Основные типы данных
Как и большинство языков, python имеет ряд основных типов: int, floats, booleans и strings.
Эти типы данных ведут себя так же, как и в большинстве других языков программирования.
Числа:
x = 3
print(type(x)) # Prints "<class 'int'>"
print(x) # Prints "3"
print(x + 1) # Addition; prints "4"
print(x - 1) # Subtraction; prints "2"
print(x * 2) # Multiplication; prints "6"
print(x ** 2) # Exponentiation; prints "9"
x += 1
print(x) # Prints "4"
x *= 2
print(x) # Prints "8"
y = 2.5
print(type(y)) # Prints "<class 'float'>"
print(y, y + 1, y * 2, y ** 2) # Prints "2.5 3.5 5.0 6.25"
Обратите внимание, что в отличие от многих языков, в python нет унарного инкремента (x++) или декремента (x--).
Python также имеет встроенные типы для комплексных чисел;
Все подробности можно найти в документации.
Логический тип данных: python реализует все обычные операторы для булевой логики, но использует английские слова, а не символы (&&, || , и т. д.):
t = True
f = False
print(type(t)) # Prints "<class 'bool'>"
print(t and f) # Logical AND; prints "False"
print(t or f) # Logical OR; prints "True"
print(not t) # Logical NOT; prints "False"
print(t != f) # Logical XOR; prints "True"
Строки: python имеет отличную поддержку строк:
hello = 'hello' # String literals can use single quotes
world = "world" # or double quotes; it does not matter.
print(hello) # Prints "hello"
print(len(hello)) # String length; prints "5"
hw = hello + ' ' + world # String concatenation
print(hw) # prints "hello world"
hw12 = '%s %s %d' % (hello, world, 12) # sprintf style string formatting
print(hw12) # prints "hello world 12"
Строковые объекты имеют множество полезных методов:
s = "hello"
print(s.capitalize()) # Capitalize a string; prints "Hello"
print(s.upper()) # Convert a string to uppercase; prints "HELLO"
print(s.rjust(7)) # Right-justify a string, padding with spaces; prints " hello"
print(s.center(7)) # Center a string, padding with spaces; prints " hello "
print(s.replace('l', '(ell)')) # Replace all instances of one substring with another;
# prints "he(ell)(ell)o"
print(' world '.strip()) # Strip leading and trailing whitespace; prints "world"
Список всех строковых методов можно найти в документации.
Контейнеры
Python включает в себя несколько встроенных типов контейнеров: списки, словари, наборы и кортежи.
Списки
Список в python является эквивалентом массива, но его размер можно изменять и он можетё содержать элементы разных типов:
xs = [3, 1, 2] # Create a list
print(xs, xs[2]) # Prints "[3, 1, 2] 2"
print(xs[-1]) # Negative indices count from the end of the list; prints "2"
xs[2] = 'foo' # Lists can contain elements of different types
print(xs) # Prints "[3, 1, 'foo']"
xs.append('bar') # Add a new element to the end of the list
print(xs) # Prints "[3, 1, 'foo', 'bar']"
x = xs.pop() # Remove and return the last element of the list
print(x, xs) # Prints "bar [3, 1, 'foo']"
Как обычно, вы можете найти подробности о списках в документации.
Разрезание на ломтики: В дополнение к доступу к элементам списка по одному, python предоставляет лаконичный синтаксис для доступа к подспискам; Это называется нарезкой:
nums = list(range(5)) # range is a built-in function that creates a list of integers
print(nums) # Prints "[0, 1, 2, 3, 4]"
print(nums[2:4]) # Get a slice from index 2 to 4 (exclusive); prints "[2, 3]"
print(nums[2:]) # Get a slice from index 2 to the end; prints "[2, 3, 4]"
print(nums[:2]) # Get a slice from the start to index 2 (exclusive); prints "[0, 1]"
print(nums[:]) # Get a slice of the whole list; prints "[0, 1, 2, 3, 4]"
print(nums[:-1]) # Slice indices can be negative; prints "[0, 1, 2, 3]"
nums[2:4] = [8, 9] # Assign a new sublist to a slice
print(nums) # Prints "[0, 1, 8, 9, 4]"
Мы снова увидим нарезку в контексте массивов numpy.
Петли: Вы можете перебирать элементы списка следующим образом:
animals = ['cat', 'dog', 'monkey']
for animal in animals:
print(animal)
# Prints "cat", "dog", "monkey", each on its own line.
Если вы хотите получить доступ к индексу каждого элемента в теле цикла, воспользуйтесь встроенной функцией:enumerate
animals = ['cat', 'dog', 'monkey']
for idx, animal in enumerate(animals):
print('#%d: %s' % (idx + 1, animal))
# Prints "#1: cat", "#2: dog", "#3: monkey", each on its own line
Список включений: при программировании мы часто хотим преобразовать один тип данных в другой. В качестве простого примера рассмотрим следующий код, который вычисляет квадратные числа:
nums = [0, 1, 2, 3, 4]
squares = []
for x in nums:
squares.append(x ** 2)
print(squares) # Prints [0, 1, 4, 9, 16]
Вы можете упростить этот код с помощью спискового понимания:
nums = [0, 1, 2, 3, 4]
squares = [x ** 2 for x in nums]
print(squares) # Prints [0, 1, 4, 9, 16]
Включения списка также могут содержать условия:
nums = [0, 1, 2, 3, 4]
even_squares = [x ** 2 for x in nums if x % 2 == 0]
print(even_squares) # Prints "[0, 4, 16]"
Словари
Словарь хранит пары (ключ, значение), аналогично Map в Java или объекту в Javascript. Вы можете использовать его следующим образом:
d = {'cat': 'cute', 'dog': 'furry'} # Create a new dictionary with some data
print(d['cat']) # Get an entry from a dictionary; prints "cute"
print('cat' in d) # Check if a dictionary has a given key; prints "True"
d['fish'] = 'wet' # Set an entry in a dictionary
print(d['fish']) # Prints "wet"
# print(d['monkey']) # KeyError: 'monkey' not a key of d
print(d.get('monkey', 'N/A')) # Get an element with a default; prints "N/A"
print(d.get('fish', 'N/A')) # Get an element with a default; prints "wet"
del d['fish'] # Remove an element from a dictionary
print(d.get('fish', 'N/A')) # "fish" is no longer a key; prints "N/A"
Все, что вам нужно знать о словарях, вы можете найти в документации.
Петли: Перебирать ключи в словаре очень просто:
d = {'person': 2, 'cat': 4, 'spider': 8}
for animal in d:
legs = d[animal]
print('A %s has %d legs' % (animal, legs))
# Prints "A person has 2 legs", "A cat has 4 legs", "A spider has 8 legs"
Если вы хотите получить доступ к ключам и их соответствующим значениям, используйте метод:items
d = {'person': 2, 'cat': 4, 'spider': 8}
for animal, legs in d.items():
print('A %s has %d legs' % (animal, legs))
# Prints "A person has 2 legs", "A cat has 4 legs", "A spider has 8 legs"
Словарное понимание: Они похожи на включения списков, но позволяют легко создавать cловари. Например:
nums = [0, 1, 2, 3, 4]
even_num_to_square = {x: x ** 2 for x in nums if x % 2 == 0}
print(even_num_to_square) # Prints "{0: 0, 2: 4, 4: 16}"
Наборы
Наборы — это неупорядоченное множество отдельных элементов. В качестве простого примера рассмотрим следующее:
animals = {'cat', 'dog'}
print('cat' in animals) # Check if an element is in a set; prints "True"
print('fish' in animals) # prints "False"
animals.add('fish') # Add an element to a set
print('fish' in animals) # Prints "True"
print(len(animals)) # Number of elements in a set; prints "3"
animals.add('cat') # Adding an element that is already in the set does nothing
print(len(animals)) # Prints "3"
animals.remove('cat') # Remove an element from a set
print(len(animals)) # Prints "2"
Как обычно, все, что вы хотите знать о множествах, можно найти в документации.
Петли: Перебор набора имеет тот же синтаксис, что и перебор списка;
Однако, поскольку наборы не упорядочены, вы не можете делать предположения о порядке, в которых вы посещаете элементы набора:
animals = {'cat', 'dog', 'fish'}
for idx, animal in enumerate(animals):
print('#%d: %s' % (idx + 1, animal))
# Prints "#1: fish", "#2: dog", "#3: cat"
Набор понятий: подобно спискам и словарям, мы можем легко создавать наборы, используя включения множеств:
from math import sqrt
nums = {int(sqrt(x)) for x in range(30)}
print(nums) # Prints "{0, 1, 2, 3, 4, 5}"
Кортежи
Кортеж — это (неизменяемый) упорядоченный список значений. Кортеж во многом похож на список; Одним из наиболее важных отличий является то, что кортежи можно использовать как ключи в словарях и как элементы множеств, а списки — нет. Вот банальный пример:
d = {(x, x + 1): x for x in range(10)} # Create a dictionary with tuple keys
t = (5, 6) # Create a tuple
print(type(t)) # Prints "<class 'tuple'>"
print(d[t]) # Prints "5"
print(d[(1, 2)]) # Prints "1"
В документации есть больше информации о кортежах.
Функции
Функции python определяются с помощью ключевого слова. Например:def
def sign(x):
if x > 0:
return 'positive'
elif x < 0:
return 'negative'
else:
return 'zero'
for x in [-1, 0, 1]:
print(sign(x))
# Prints "negative", "zero", "positive"
Мы часто определяем функции, принимающие необязательные аргументы ключевых слов, например:
def hello(name, loud=False):
if loud:
print('HELLO, %s!' % name.upper())
else:
print('Hello, %s' % name)
hello('Bob') # Prints "Hello, Bob"
hello('Fred', loud=True) # Prints "HELLO, FRED!"
В документации есть гораздо больше информации о функциях python.
Классы
Синтаксис для определения классов в python прост:
class Greeter(object):
# Constructor
def **init**(self, name):
self.name = name # Create an instance variable
# Instance method
def greet(self, loud=False):
if loud:
print('HELLO, %s!' % self.name.upper())
else:
print('Hello, %s' % self.name)
g = Greeter('Fred') # Construct an instance of the Greeter class
g.greet() # Call an instance method; prints "Hello, Fred"
g.greet(loud=True) # Call an instance method; prints "HELLO, FRED!"
Вы можете прочитать гораздо больше о классах python в документации.
Numpy
Numpy — это основная библиотека для научных вычислений на языке python. Она предоставляет высокопроизводительный многомерный массив объектов и инструменты для работы с ними Массивы. Если вы уже знакомы с MATLAB, то этот урок может быть вам полезен для начала работы с Numpy.
Массивы
Массив numpy представляет собой сетку значений одного и того же типа, индексирующую кортежем неотрицательные целые числа. Количество измерений — это ранг массива; Форма массива представляет собой кортеж целых чисел, задающий размер массива вдоль каждого измерения.
Мы можем инициализировать массивы numpy из вложенных списков python, и получить доступ к элементам с помощью квадратных скобок:
import numpy as np
a = np.array([1, 2, 3]) # Create a rank 1 array
print(type(a)) # Prints "<class 'numpy.ndarray'>"
print(a.shape) # Prints "(3,)"
print(a[0], a[1], a[2]) # Prints "1 2 3"
a[0] = 5 # Change an element of the array
print(a) # Prints "[5, 2, 3]"
b = np.array([[1,2,3],[4,5,6]]) # Create a rank 2 array
print(b.shape) # Prints "(2, 3)"
print(b[0, 0], b[0, 1], b[1, 0]) # Prints "1 2 4"
Numpy также предоставляет множество функций для создания массивов:
import numpy as np
a = np.zeros((2,2)) # Create an array of all zeros
print(a) # Prints "[[ 0. 0.]
# [ 0. 0.]]"
b = np.ones((1,2)) # Create an array of all ones
print(b) # Prints "[[ 1. 1.]]"
c = np.full((2,2), 7) # Create a constant array
print(c) # Prints "[[ 7. 7.]
# [ 7. 7.]]"
d = np.eye(2) # Create a 2x2 identity matrix
print(d) # Prints "[[ 1. 0.]
# [ 0. 1.]]"
e = np.random.random((2,2)) # Create an array filled with random values
print(e) # Might print "[[ 0.91940167 0.08143941]
# [ 0.68744134 0.87236687]]"
О других способах создания массивов вы можете прочитать в документации.
Индексация массивов
Numpy предлагает несколько способов индексации в массивы.
Разрезание на ломтики: как и в случае со списками python, массивы numpy могут быть разделены на срезы. Поскольку массивы могут быть многомерными, необходимо указать срез для каждого измерения массива:
import numpy as np
# Create the following rank 2 array with shape (3, 4)
# [[ 1 2 3 4]
# [ 5 6 7 8]
# [ 9 10 11 12]]
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
# Use slicing to pull out the subarray consisting of the first 2 rows
# and columns 1 and 2; b is the following array of shape (2, 2):
# [[2 3]
# [6 7]]
b = a[:2, 1:3]
# A slice of an array is a view into the same data, so modifying it
# will modify the original array.
print(a[0, 1]) # Prints "2"
b[0, 0] = 77 # b[0, 0] is the same piece of data as a[0, 1]
print(a[0, 1]) # Prints "77"
Вы также можете сочетать целочисленное индексирование с индексированием срезов. Однако это приведет к получению массива более низкого ранга, чем исходный массив. Обратите внимание, что это сильно отличается от способа, которым MATLAB работает с массивами при разрезании на ломтики:
import numpy as np
# Create the following rank 2 array with shape (3, 4)
# [[ 1 2 3 4]
# [ 5 6 7 8]
# [ 9 10 11 12]]
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
# Two ways of accessing the data in the middle row of the array.
# Mixing integer indexing with slices yields an array of lower rank,
# while using only slices yields an array of the same rank as the
# original array:
row_r1 = a[1, :] # Rank 1 view of the second row of a
row_r2 = a[1:2, :] # Rank 2 view of the second row of a
print(row_r1, row_r1.shape) # Prints "[5 6 7 8] (4,)"
print(row_r2, row_r2.shape) # Prints "[[5 6 7 8]] (1, 4)"
# We can make the same distinction when accessing columns of an array:
col_r1 = a[:, 1]
col_r2 = a[:, 1:2]
print(col_r1, col_r1.shape) # Prints "[ 2 6 10] (3,)"
print(col_r2, col_r2.shape) # Prints "[[ 2]
# [ 6]
# [10]] (3, 1)"
Индексация целочисленного массива: Когда вы индексируете массивы numpy с помощью слайсинга, результирующее представление массива всегда будет подмассивом исходного массива. В противоположность этому, индексация целочисленного массива позволяет создавать произвольные массивы, используя данные из другого массива. Вот пример:
import numpy as np
a = np.array([[1,2], [3, 4], [5, 6]])
# An example of integer array indexing.
# The returned array will have shape (3,) and
print(a[[0, 1, 2], [0, 1, 0]]) # Prints "[1 4 5]"
# The above example of integer array indexing is equivalent to this:
print(np.array([a[0, 0], a[1, 1], a[2, 0]])) # Prints "[1 4 5]"
# When using integer array indexing, you can reuse the same
# element from the source array:
print(a[[0, 0], [1, 1]]) # Prints "[2 2]"
# Equivalent to the previous integer array indexing example
print(np.array([a[0, 1], a[0, 1]])) # Prints "[2 2]"
Одним из полезных приемов при индексации целочисленных массивов является выбор или изменение в одногм из них каждой строки матрицы:
import numpy as np
# Create a new array from which we will select elements
a = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
print(a) # prints "array([[ 1, 2, 3],
# [ 4, 5, 6],
# [ 7, 8, 9],
# [10, 11, 12]])"
# Create an array of indices
b = np.array([0, 2, 0, 1])
# Select one element from each row of a using the indices in b
print(a[np.arange(4), b]) # Prints "[ 1 6 7 11]"
# Mutate one element from each row of a using the indices in b
a[np.arange(4), b] += 10
print(a) # prints "array([[11, 2, 3],
# [ 4, 5, 16],
# [17, 8, 9],
# [10, 21, 12]])
Индексация логических массивов: Логическое индексирование массива позволяет выделять произвольные элементы массива. Часто этот тип индексации используется для выбора элементов массива которые удовлетворяют какому-либо условию. Вот пример:
import numpy as np
a = np.array([[1,2], [3, 4], [5, 6]])
bool_idx = (a > 2) # Find the elements of a that are bigger than 2;
# this returns a numpy array of Booleans of the same
# shape as a, where each slot of bool_idx tells
# whether that element of a is > 2.
print(bool_idx) # Prints "[[False False]
# [ True True]
# [ True True]]"
# We use boolean array indexing to construct a rank 1 array
# consisting of the elements of a corresponding to the True values
# of bool_idx
print(a[bool_idx]) # Prints "[3 4 5 6]"
# We can do all of the above in a single concise statement:
print(a[a > 2]) # Prints "[3 4 5 6]"
Для краткости мы опустили много подробностей об индексации массива numpy; Если вы хотите узнать больше, вам следует прочитать документацию.
Типы данных
Каждый массив numpy представляет собой сетку элементов одного типа. Numpy предоставляет большой набор числовых типов данных, которые можно использовать для создания массивов. Numpy пытается определить тип данных при создании массива, но функции, создающие массивы, обычно также включают необязательный аргумент для явного указания типа данных. Вот пример:
import numpy as np
x = np.array([1, 2]) # Let numpy choose the datatype
print(x.dtype) # Prints "int64"
x = np.array([1.0, 2.0]) # Let numpy choose the datatype
print(x.dtype) # Prints "float64"
x = np.array([1, 2], dtype=np.int64) # Force a particular datatype
print(x.dtype) # Prints "int64"
Вы можете прочитать все о типах данных numpy в документации.
Математические операции с массивами
Основные математические функции работают с массивами поэлементно и доступны как в виде перегрузок операторов, так и в виде функций в модуле numpy:
import numpy as np
x = np.array([[1,2],[3,4]], dtype=np.float64)
y = np.array([[5,6],[7,8]], dtype=np.float64)
# Elementwise sum; both produce the array
# [[ 6.0 8.0]
# [10.0 12.0]]
print(x + y)
print(np.add(x, y))
# Elementwise difference; both produce the array
# [[-4.0 -4.0]
# [-4.0 -4.0]]
print(x - y)
print(np.subtract(x, y))
# Elementwise product; both produce the array
# [[ 5.0 12.0]
# [21.0 32.0]]
print(x * y)
print(np.multiply(x, y))
# Elementwise division; both produce the array
# [[ 0.2 0.33333333]
# [ 0.42857143 0.5 ]]
print(x / y)
print(np.divide(x, y))
# Elementwise square root; produces the array
# [[ 1. 1.41421356]
# [ 1.73205081 2. ]]
print(np.sqrt(x))
Обратите внимание, что в отличие от MATLAB,*- это поэлементное умножение, а не матрица умножение. Вместо этого мы используем функцию dot для вычисления скалярного произведения векторов, умножить вектор на матрицу, и умножения матриц. dot доступен как функция в numpy и в качестве экземпляра метода объектов массива:
import numpy as np
x = np.array([[1,2],[3,4]])
y = np.array([[5,6],[7,8]])
v = np.array([9,10])
w = np.array([11, 12])
# Inner product of vectors; both produce 219
print(v.dot(w))
print(np.dot(v, w))
# Matrix / vector product; both produce the rank 1 array [29 67]
print(x.dot(v))
print(np.dot(x, v))
# Matrix / matrix product; both produce the rank 2 array
# [[19 22]
# [43 50]]
print(x.dot(y))
print(np.dot(x, y))
Numpy предоставляет множество полезных функций для выполнения вычислений на массивах; Одной из самых полезных является:sum
import numpy as np
x = np.array([[1,2],[3,4]])
print(np.sum(x)) # Compute sum of all elements; prints "10"
print(np.sum(x, axis=0)) # Compute sum of each column; prints "[4 6]"
print(np.sum(x, axis=1)) # Compute sum of each row; prints "[3 7]"
Полный список математических функций, предоставляемых numpy, вы можете найти в документации.
Помимо вычисления математических функций с помощью массивов, мы часто должны изменять форму данных в массивах или иным образом манипулировать ими. Самый простой пример. Одним из таких видов операции является транспонирование матрицы; для транспонирования матрицы, просто используйте атрибут T объекта массива:
import numpy as np
x = np.array([[1,2], [3,4]])
print(x) # Prints "[[1 2]
# [3 4]]"
print(x.T) # Prints "[[1 3]
# [2 4]]"
# Note that taking the transpose of a rank 1 array does nothing:
v = np.array([1,2,3])
print(v) # Prints "[1 2 3]"
print(v.T) # Prints "[1 2 3]"
Numpy предоставляет гораздо больше функций для работы с массивами; С полным списком можно ознакомиться в документации.
Вещание
Вещание - это мощный механизм, который позволяет numpy работать с массивами различных фигур при выполнении арифметических действий. Часто у нас есть меньший массив и больший массив, и мы хотим использовать меньший массив несколько раз для выполнения какой-либо операции на более крупном массиве.
Например, предположим, что мы хотим добавить вектор константы к каждой строке матрицы. Мы могли бы сделать это следующим образом:
import numpy as np
# We will add the vector v to each row of the matrix x,
# storing the result in the matrix y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
y = np.empty_like(x) # Create an empty matrix with the same shape as x
# Add the vector v to each row of the matrix x with an explicit loop
for i in range(4):
y[i, :] = x[i, :] + v
# Now y is the following
# [[ 2 2 4]
# [ 5 5 7]
# [ 8 8 10]
# [11 11 13]]
print(y)
Это работает, однако, когда матрица x очень большая, вычисление явного цикла в python может быть медленным. Обратите внимание, что добавление вектора v к каждой строке матрицы x эквивалентно формированию матрицы vv путем наложения нескольких копий v по вертикали, затем выполнение поэлементного суммирования x и vv мы могли бы реализовать этот подход следующим образом:
import numpy as np
# We will add the vector v to each row of the matrix x,
# storing the result in the matrix y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
vv = np.tile(v, (4, 1)) # Stack 4 copies of v on top of each other
print(vv) # Prints "[[1 0 1]
# [1 0 1]
# [1 0 1]
# [1 0 1]]"
y = x + vv # Add x and vv elementwise
print(y) # Prints "[[ 2 2 4
# [ 5 5 7]
# [ 8 8 10]
# [11 11 13]]"
Массивы Numpy позволяют выполнять вычисления без фактического создания нескольких копий v. Рассмотрим эту версию с использованием массивов:
import numpy as np
# We will add the vector v to each row of the matrix x,
# storing the result in the matrix y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
y = x + v # Add v to each row of x using broadcasting
print(y) # Prints "[[ 2 2 4]
# [ 5 5 7]
# [ 8 8 10]
# [11 11 13]]"
Строка y = x + v работает, несмотря на то, что x имеет форму (4, 3)и v имеет форму (3,) благодаря вещанию; Эта линия работает так, как будто v на самом деле имеет форму (4, 3), где каждая строка была копией , а сумма v выполнялась по элементам.
Трансляция двух массивов одновременно выполняется по следующим правилам:
1. Если массивы имеют разный ранг, добавьте в начало форму массива с меньшим рангом с 1s до тех пор, пока обе фигуры не будут иметь одинаковую длину.
2. Два массива считаются совместимыми в размерности, если они имеют одинаковое значение size в измерении, или если один из массивов имеет размер 1 в этом измерении.
3. Массивы могут транслироваться вместе, если они совместимы во всех измерениях.
4. После трансляции каждый массив ведет себя так, как если бы он имел форму, равную поэлементной максимальное количество форм двух входных массивов.
5. В любом измерении, где один массив имеет размер 1, а другой массив больше 1, первый массив ведет себя так, как если бы он был скопирован по этому размеру
Если это объяснение не имеет смысла, попробуйте прочитать объяснение из документации или это объяснение.
Функции, поддерживающие широковещательную рассылку, называются универсальными функциями. Вы можете найти Список всех универсальных функций в документации.
Вот некоторые области применения вещания:
import numpy as np
# Compute outer product of vectors
v = np.array([1,2,3]) # v has shape (3,)
w = np.array([4,5]) # w has shape (2,)
# To compute an outer product, we first reshape v to be a column
# vector of shape (3, 1); we can then broadcast it against w to yield
# an output of shape (3, 2), which is the outer product of v and w:
# [[ 4 5]
# [ 8 10]
# [12 15]]
print(np.reshape(v, (3, 1)) * w)
# Add a vector to each row of a matrix
x = np.array([[1,2,3], [4,5,6]])
# x has shape (2, 3) and v has shape (3,) so they broadcast to (2, 3),
# giving the following matrix:
# [[2 4 6]
# [5 7 9]]
print(x + v)
# Add a vector to each column of a matrix
# x has shape (2, 3) and w has shape (2,).
# If we transpose x then it has shape (3, 2) and can be broadcast
# against w to yield a result of shape (3, 2); transposing this result
# yields the final result of shape (2, 3) which is the matrix x with
# the vector w added to each column. Gives the following matrix:
# [[ 5 6 7]
# [ 9 10 11]]
print((x.T + w).T)
# Another solution is to reshape w to be a column vector of shape (2, 1);
# we can then broadcast it directly against x to produce the same
# output.
print(x + np.reshape(w, (2, 1)))
# Multiply a matrix by a constant:
# x has shape (2, 3). Numpy treats scalars as arrays of shape ();
# these can be broadcast together to shape (2, 3), producing the
# following array:
# [[ 2 4 6]
# [ 8 10 12]]
print(x * 2)
Широковещательная рассылка обычно делает ваш код более кратким и быстрым, поэтому вы должен стремиться использовать ее там, где это возможно.
Документация Numpy
Этот краткий обзор затронул многие важные вещи, которые вам необходимо знать о numpy, но далеко не полны. Ознакомьтесь со справочником numpy, чтобы узнать больше о numpy.
SciPy
Numpy предоставляет высокопроизводительный многомерный массив и основные инструменты для выполняйте вычисления с помощью этих массивов и управляйте ими.
SciPy опирается на это и предоставляет большое количество функций, которые работают с массивами numpy и полезны для различных видов научных и инженерных приложений.
Лучший способ познакомиться с SciPy - это просмотреть документацию.
Мы выделим некоторые части SciPy, которые могут быть вам полезны для этого класса.
Операции с изображениями
SciPy предоставляет некоторые основные функции для работы с изображениями.
Например, в нем есть функции чтения изображений с диска в массивы numpy, для записи массивов numpy на диск в виде изображений, а также для изменения размера изображений.
Вот простой пример, демонстрирующий эти функции:
from scipy.misc import imread, imsave, imresize
# Read an JPEG image into a numpy array
img = imread('assets/cat.jpg')
print(img.dtype, img.shape) # Prints "uint8 (400, 248, 3)"
# We can tint the image by scaling each of the color channels
# by a different scalar constant. The image has shape (400, 248, 3);
# we multiply it by the array [1, 0.95, 0.9] of shape (3,);
# numpy broadcasting means that this leaves the red channel unchanged,
# and multiplies the green and blue channels by 0.95 and 0.9
# respectively.
img_tinted = img * [1, 0.95, 0.9]
# Resize the tinted image to be 300 by 300 pixels.
img_tinted = imresize(img_tinted, (300, 300))
# Write the tinted image back to disk
imsave('assets/cat_tinted.jpg', img_tinted)


Сверху: исходное изображение. Снизу: Затемненное изображение с измененным размером.
Файлы MATLAB
Функции scipy.io.loadmat и scipy.io.savemat позволяют считывать и писать файлы MATLAB. О них можно прочитать в документации.
Расстояние между точками
SciPy определяет некоторые полезные функции для вычисления расстояний между наборами точек.
Функция scipy.spatial.distance.pdist вычисляет расстояние между всеми парами точек в заданном наборе:
import numpy as np
from scipy.spatial.distance import pdist, squareform
# Create the following array where each row is a point in 2D space:
# [[0 1]
# [1 0]
# [2 0]]
x = np.array([[0, 1], [1, 0], [2, 0]])
print(x)
# Compute the Euclidean distance between all rows of x.
# d[i, j] is the Euclidean distance between x[i, :] and x[j, :],
# and d is the following array:
# [[ 0. 1.41421356 2.23606798]
# [ 1.41421356 0. 1. ]
# [ 2.23606798 1. 0. ]]
d = squareform(pdist(x, 'euclidean'))
print(d)
Все подробности об этой функции вы можете прочитать в документации.
Аналогичная функция (scipy.spatial.distance.cdist) вычисляет расстояние между всеми парами по двум группам точек; Вы можете прочитать об этом в документации .
Matplotlib
Matplotlib — библиотека для построения графиков. В этом разделе дается краткое введение в модуль matplotlib.pyplot, который обеспечивает систему построения графиков, аналогичную системе MATLAB.
Постоение графиков
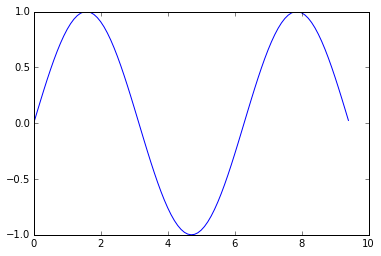
Наиболее важной функцией в matplotlib является plot, что позволяет строить графики 2D данных. Вот простой пример:
import numpy as np
import matplotlib.pyplot as plt
# Compute the x and y coordinates for points on a sine curve
x = np.arange(0, 3 * np.pi, 0.1)
y = np.sin(x)
# Plot the points using matplotlib
plt.plot(x, y)
plt.show() # You must call plt.show() to make graphics appear.
Выполнение этого кода создает следующий график:
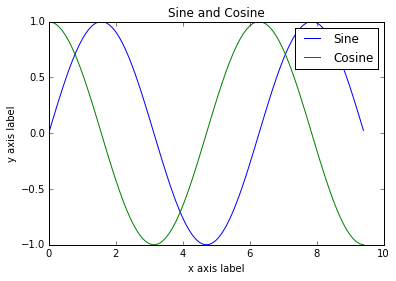
Приложив немного дополнительной работы, мы можем легко построить несколько линий и добавить заголовок, легенду и подписи осям:
import numpy as np
import matplotlib.pyplot as plt
# Compute the x and y coordinates for points on sine and cosine curves
x = np.arange(0, 3 * np.pi, 0.1)
y_sin = np.sin(x)
y_cos = np.cos(x)
# Plot the points using matplotlib
plt.plot(x, y_sin)
plt.plot(x, y_cos)
plt.xlabel('x axis label')
plt.ylabel('y axis label')
plt.title('Sine and Cosine')
plt.legend(['Sine', 'Cosine'])
plt.show()
Гораздо больше о функции plot вы можете прочитать в документации.
Подзаголовки
С помощью subplot функции на одном и том же рисунке можно изобразить разные объекты. Вот пример:
import numpy as np
import matplotlib.pyplot as plt
# Compute the x and y coordinates for points on sine and cosine curves
x = np.arange(0, 3 * np.pi, 0.1)
y_sin = np.sin(x)
y_cos = np.cos(x)
# Set up a subplot grid that has height 2 and width 1,
# and set the first such subplot as active.
plt.subplot(2, 1, 1)
# Make the first plot
plt.plot(x, y_sin)
plt.title('Sine')
# Set the second subplot as active, and make the second plot.
plt.subplot(2, 1, 2)
plt.plot(x, y_cos)
plt.title('Cosine')
# Show the figure.
plt.show()
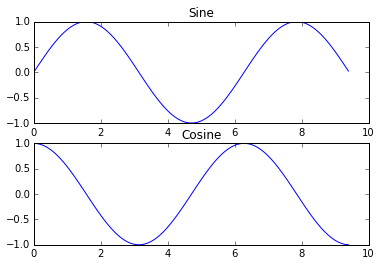
Гораздо больше о функции subplot вы можете прочитать в документации.
Изображения
Вы можете использовать функцию imshow для показа изображений. Вот пример:
import numpy as np
from scipy.misc import imread, imresize
import matplotlib.pyplot as plt
img = imread('assets/cat.jpg')
img_tinted = img * [1, 0.95, 0.9]
# Show the original image
plt.subplot(1, 2, 1)
plt.imshow(img)
# Show the tinted image
plt.subplot(1, 2, 2)
# A slight gotcha with imshow is that it might give strange results
# if presented with data that is not uint8. To work around this, we
# explicitly cast the image to uint8 before displaying it.
plt.imshow(np.uint8(img_tinted))
plt.show()