Классификация изображений
Классификация изображений
В этой лекции мы познакомимся с проблемой классификации изображений. Решение проблемы заключается в подходе, основанном на большом объеме размеченных данных.
Содержание:
- Введение в классификацию изображений
- Классификатор ближайшего соседа
- Классификатор k - ближайших соседей
- Наборы данных для настройки гиперпараметров
- Применение kNN на практике
- Дополнительные материалы
Введение в классификацию изображений
Мотивация. В этом разделе мы рассмотрим задачу классификации изображений. Задача заключается в присвоении входному изображению одной метки из фиксированного набора категорий. Это одна из основных задач компьютерного зрения, которая, несмотря на свою простоту, имеет множество практических применений. Более того, многие другие задачи компьютерного зрения (детекция объектов, сегментация) могут быть сведены к классификации изображений.
Пример. Например, на изображении ниже модель классификации изображений принимает одно изображение и присваивает вероятности четырём меткам: {«кошка», «собака», «шляпа», «кружка»}. Как показано на изображении, для компьютера изображение представляет собой один большой трёхмерный массив чисел. В этом примере изображение кошки имеет ширину 248 пикселей, высоту 400 пикселей и три цветовых канала: красный, зелёный, синий (или сокращённо RGB). Таким образом, изображение состоит из 248 x 400 x 3 чисел, или в общей сложности 297 600 чисел. Каждое число представляет собой целое число от 0 (чёрный) до 255 (белый). Наша задача — превратить эти четверть миллиона чисел в одну метку, например «кошка».
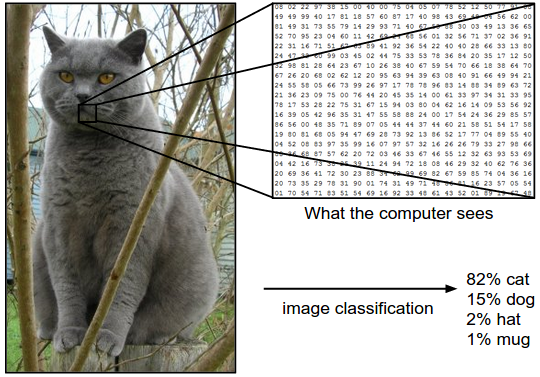
Задача классификации изображений состоит в том, чтобы предсказать одну метку для заданного изображения. Так же мы можем предсказать распределение вероятностей для всех меток, что отражает степень нашей уверенности в результате классификации. Изображения представляют собой трёхмерные массивы целых чисел от 0 до 255 размером «ширина x высота x 3». Число 3 обозначает три цветовых канала: красный, зелёный и синий.
Проблемы. Поскольку задача распознавания визуального образа (например, кошки) относительно проста для человека, стоит рассмотреть связанные с ней проблемы с точки зрения алгоритма компьютерного зрения.
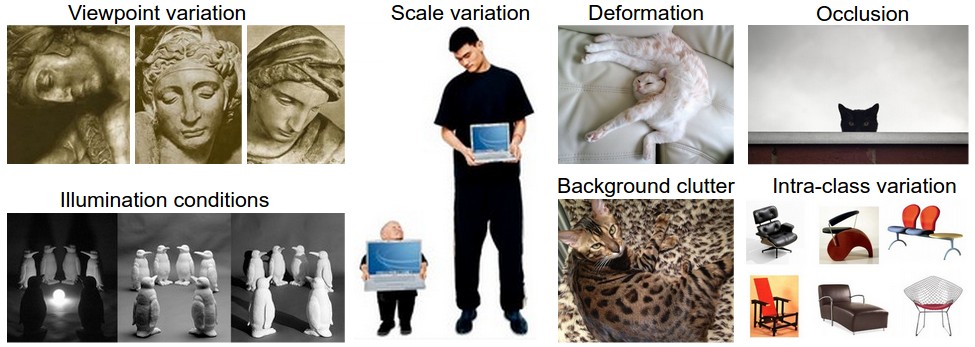
Ниже мы приводим (неполный) список проблем, не забывая о том, что изображения представлены в виде трёхмерного массива значений яркости:
- Изменение точки обзора. Один экземпляр объекта может быть ориентирован по-разному относительно камеры.
- Изменение масштаба. Визуальные классы часто различаются по размеру (размеру в реальном мире, а не только по размеру на изображении).
- Деформация. Многие интересующие нас объекты не являются твёрдыми телами и могут сильно деформироваться.
- Окклюзия. Интересующие нас объекты могут быть частично скрыты. Иногда видна лишь небольшая часть объекта (всего несколько пикселей).
- Условия освещения. Влияние освещения на пиксели очень велико.
- Фоновый шум. Интересующие нас объекты могут сливаться с окружающей средой, что затрудняет их идентификацию.
- Внутриклассовые различия. Классы, представляющие интерес, часто могут быть относительно обширными, например, стулья.
Существует множество различных типов этих предметов, каждый из которых имеет отличный от других элементов класса внешний вид.
Хорошая модель классификации изображений должна быть инвариантна к перекрёстному произведению всех этих вариаций, сохраняя при этом чувствительность к межклассовым вариациям.
Подход, основанный на данных. Как бы мы могли написать алгоритм, который сможет классифицировать изображения по отдельным категориям? В отличие от написания алгоритма, например, для сортировки списка чисел, не очевидно, как можно написать алгоритм для распознавания кошек на изображениях. Поэтому вместо того, чтобы пытаться описать каждую из интересующих нас категорий непосредственно в коде, мы воспользуемся подходом, похожим на обучение ребёнка. Мы предоставим компьютеру множество примеров, а затем используем алгоритм обучения, который связывает визуальное представление с меткой каждого класса. Этот подход предполагает, что у нас есть обучающий набор с размеченными изображениями. Вот пример того, как может выглядеть такой набор данных:
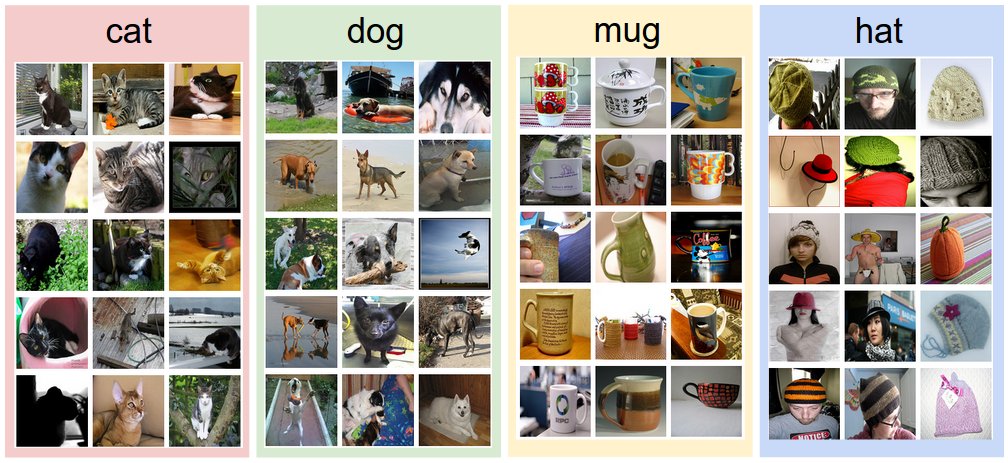
Пример обучающего набора для четырёх визуальных категорий. На практике у нас могут быть тысячи категорий и сотни тысяч изображений для каждой категории.
Конвейер классификации изображений. Мы увидели, что задача классификации изображений состоит в том, чтобы взять массив пикселей изображения и присвоить ему метку.
Наш полный конвейер можно формализовать следующим образом:
- Входные данные: состоят из набора N изображений, каждое из которых помечено одним из K различных классов.
Эти данные называются обучающей выборкой.
- Обучение: наша задача использовать обучающую выборку, чтобы узнать, как выглядит каждый из классов.
Мы называем этот этап обучением классификатора или обучением модели.
- Оценка: в конце мы оцениваем качество классификатора.
Для этого нужно задать вопрос о том, какие метки предскажет классификатор для нового набора изображений, которые он никогда раньше не видел.
Затем мы сравниваем истинные метки этих изображений с теми, которые предсказал классификатор.
Интуитивно мы надеемся, что многие прогнозы совпадут с истинными ответами.
Данные, которые используются для оценки точности классификатора называются тестовой выборкой.
Классификатор ближайшего соседа
В качестве первого подхода мы используем так называемый классификатор ближайшего соседа. Этот классификатор не имеет ничего общего со свёрточными нейронными сетями и очень редко используется на практике. Однако он позволит нам получить представление о том, как решается задача классификации изображений.
Пример набора данных для классификации изображений: CIFAR-10.
Одним из популярных наборов данных для классификации изображений является набор данных CIFAR-10. Этот набор данных состоит из 60 000 крошечных изображений высотой и шириной 32 пикселя. Каждое изображение относится к одному из 10 классов: самолет, автомобиль, птица и т. д. Эти 60 000 изображений разделены на обучающую выборку из 50 000 изображений и тестовую выборку из 10 000 изображений.
На изображении ниже вы можете увидеть 10 случайных примеров изображений для каждого класса.

Слева: примеры изображений из набора данных CIFAR-10.
Справа: в первом столбце показаны несколько тестовых изображений.
Рядом с каждым изображением мы видим 10 наиболее похожих "картинок" из обучающей выборки.
Изначально, у нас есть обучающая выборка CIFAR-10 из 50 000 изображений (по 5000 изображений для каждой из 10 категорий). Мы хотим классифицировать оставшиеся 10 000. Классификатор ближайших соседей работает следующим образом. Берется тестовое изображение и сравается с каждым изображением из обучающей выборки. Будем считать, что метка тестового изображения будет такой же, как и у самого похожего на него изображения.
На изображении выше и справа вы можете увидеть пример результата такой процедуры для 10 тестовых изображений. Обратите внимание, что только в 3 из 10 изображений являются элементами того же класса, в то время как в остальных 7 примерах возникает ошибка определения класса. Например, в 8-м ряду ближайшим обучающим изображением к голове лошади является красный автомобиль, предположительно из-за сильного чёрного фона. В результате этого, изображение лошади в данном случае будет ошибочно помечено как автомобиль.
Мы не уточнили, как именно мы сравниваем два изображения. Технически изображения представляют собой просто два блока (тензора) размером 32 x 32 x 3. Один из самых простых способов — сравнивать изображения попиксельно и суммировать все разности. Другими словами, если у вас есть два изображения, представленные в виде векторов $I_1$, $I_2$, разумным выбором для их сравнения может быть расстояние L1:
$$ d_1 (I_1, I_2) = \sum_{p} \left| I^p_1 - I^p_2 \right| $$
Сумма берется по всем пикселям. Вот как выглядит эта процедура:
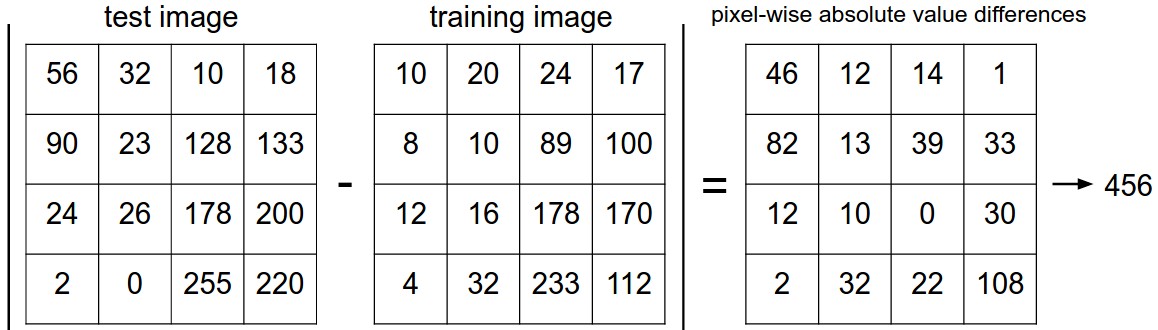
Пример использования попиксельных различий для сравнения двух изображений с помощью расстояния $L_1$ (в данном примере для одного цветового канала). Два изображения вычитаются поэлементно, а затем все различия суммируются до получения одного числа. Если два изображения идентичны, результат будет равен нулю. Но если изображения сильно отличаются, результат будет большим.
Давайте также посмотрим, как можно реализовать классификатор в коде. Сначала загрузим данные CIFAR-10 в память в виде четырех массивов: обучающие данные/метки и тестовые данные/метки. В приведенном ниже коде Xtr хранятся все изображения из обучающей выборки (объем 50 000 x 32 x 32 x 3), а соответствующий одномерный массив Ytr (длиной 50 000) содержит обучающие метки (от 0 до 9):
Xtr, Ytr, Xte, Yte = load_CIFAR10('data/cifar10/') # a magic function we provide # flatten out all images to be one-dimensional Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3) # Xtr_rows becomes 50000 x 3072 Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3) # Xte_rows becomes 10000 x 3072
Теперь, когда все изображения вытянуты в ряд, мы можем обучить и оценить классификатор:
nn = NearestNeighbor() # create a Nearest Neighbor classifier class nn.train(Xtr_rows, Ytr) # train the classifier on the training images and labels Yte_predict = nn.predict(Xte_rows) # predict labels on the test images # and now print the classification accuracy, which is the average number # of examples that are correctly predicted (i.e. label matches) print 'accuracy: %f' % ( np.mean(Yte_predict == Yte) )
Обратите внимание, что в качестве критерия оценки обычно используется метрика accuracy,
Эта метрика измеряет долю правильных прогнозов в тестовой выборке.
Обратите внимание, что все классификаторы, которые мы создадим, имеют общий интерфейс (API).
У них есть метод train(X,y), который принимает на вход данные и метки для обучения.
Внутри класса должна быть построена своего рода модель, которая предсказывает метки на основе данных.
Метод predict(X) принимает новые данные и предсказывает метки.
Пример реализации простого классификатора ближайшего соседа с расстоянием $L_1$, который реализует интерфейс классификатора:
import numpy as np class NearestNeighbor(object): def __init__(self): pass def train(self, X, y): """ X is N x D where each row is an example. Y is 1-dimension of size N The nearest neighbor classifier simply remembers all the training data """ self.Xtr = X self.ytr = y def predict(self, X): """ X is N x D where each row is an example we wish to predict label for """ num_test = X.shape[0] # lets make sure that the output type matches the input type Ypred = np.zeros(num_test, dtype = self.ytr.dtype) # loop over all test rows for i in range(num_test): # find the nearest training image to the i'th test image # using the L1 distance (sum of absolute value differences) distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1) min_index = np.argmin(distances) # get the index with smallest distance Ypred[i] = self.ytr[min_index] # predict the label of the nearest example return Ypred
Если вы запустите этот код, то увидите, что классификатор достигает точности 38,6% на тестовой выборке CIFAR-10. Это более впечатляющий результат, чем случайное угадывание (которое дало бы 10% точности для 10 классов). Но он далёк от результатов человека, которые оцениваются примерно в 94%. Еще лучший результат можно получить с помощью свёрточных нейронных сетей, которые достигают примерно 95% (см. таблицу соревнования Kaggle по CIFAR-10).
Выбор расстояния. Существует множество других способов вычисления расстояний между векторами. Одним из распространённых вариантов может быть использование расстояния $L_2$, которое имеет геометрическую интерпретацию вычисления евклидова расстояния между двумя векторами. Формула для вычисления этого расстояния имеет вид:
$$ d_2 (I_1, I_2) = \sqrt{\sum_{p} \left( I^p_1 - I^p_2 \right)^2} $$
Другими словами, мы вычисляем разницу по пикселям, как и раньше, но на этот раз возводим их в квадрат, складываем и, наконец, извлекаем квадратный корень. Используя приведенный выше код с numpy, нам нужно заменить только одну строку:
distances = np.sqrt(np.sum(np.square(self.Xtr - X[i,:]), axis = 1))
Обратите внимание на вычисление корня в функции np.sqrt.
В практической реализации метода ближайшего соседа мы могли бы не использовать операцию извлечения квадратного корня, потому что он является монотонной функцией.
То есть он масштабирует абсолютные значения расстояний, но сохраняет порядок.
Поэтому с ним или без него, ближайшие соседи будут идентичны.
Однако если применить классификатор ближайшего соседа к CIFAR-10 с $L_2$ расстоянием, получится всего 35,4% точности.
Это немного ниже, чем результат с расстоянием $L_1$.
Расстояние $L_1$ против $L_2$ . Различие между этими двумя метриками в том, что расстояние $L_2$ более строгое, чем расстояние $L_1$. Это значит, что если имеется множество небольших расхождений и всего одно большое, расстояние $L_2$ будет больше, чем $L_1$. Понятия расстояний $L_1$ и $L_2$ эквивалентно нормам, которые являются частными случаями p-нормы.
Классификатор k - ближайших соседей
Когда мы хотим сделать более точный прогноз, нам не обязательно использовать только одну метку ближайшего изображения. Действительно, почти всегда можно добиться лучшего результата, используя так называемый классификатор k-ближайших соседей. Идея очень проста: вместо того, чтобы искать одно ближайшее изображение в обучающем наборе, мы найдём k ближайших изображений. Дальше мы сравним их и устроим "голосование" за метку тестового изображения. В частности, когда k = 1, мы получаем классификатор ближайшего соседа. Интуитивно понятно, что чем больше значений k мы возьмем, тем больше будет сглаживающий эффект. Это первый пример гиперпараметра, который делает классификатор более устойчивым к ошибкам:

Пример разницы между классификатором «один ближайший сосед» и классификатором «ближайшие 5 соседей» с использованием двумерных точек и 3 классов (красный, синий, зелёный). Цветные области показывают границы решений, создаваемые классификатором с использованием расстояния $L_2$. Белые области показывают точки, которые классифицируются неоднозначно - голоса за классы равны как минимум для двух классов. Обратите внимание, что в случае классификатора 1-соседа ошибки создают небольшие островки вероятных неверных прогнозов. Например, зелёная точка в середине облака синих точек. В это же время классификатор 5-соседей сглаживает эти неровности, что, приводит к лучшему обобщению на тестовых данных. Также обратите внимание, что серые области на изображении 5-соседей вызваны равенством голосов ближайших соседей. Например, 2 соседа красные, следующие два соседа синие, последний сосед зелёный.
На практике почти всегда используется метод k-ближайших соседей. Но какое значение k следует использовать? Давайте рассмотрим этот вопрос поподробнее.
Наборы данных и настройки гиперпараметров
Классификатор k-ближайших соседей требует настройки параметра k. Интуитивно можно предположить, что существует число, которое подходит лучше всего. Кроме того, мы увидели, что существует множество различных функций расстояния, которые мы могли бы использовать: норма $L_1$, норма $L_2$, а также множество других вариантов, которые мы даже не рассматривали (например, скалярные произведения). Эти варианты называются гиперпараметрами, и они очень часто используются при разработке многих алгоритмов машинного обучения, которые обучаются на данных. Часто не очевидно, какие значения/настройки следует выбрать.
У вас может возникнуть соблазн предложить попробовать множество различных значений и посмотреть, что работает лучше всего. Это хорошая идея, и именно это мы и сделаем, но делать это нужно очень осторожно. В частности, мы не можем использовать тестовый набор данных для настройки гиперпараметров. Всякий раз, когда вы разрабатываете алгоритмы машинного обучения, вы должны относиться к тестовому набору данных как к очень ценному ресурсу, к которому, в идеале, не следует прикасаться до самого конца. В противном случае существует реальная опасность того, что вы настроите гиперпараметры так, чтобы они хорошо работали на тестовом наборе данных, но при развёртывании модели показывали значительное снижение производительности. На практике можно сказать, что произошло переобучение на тестовом наборе данных. С другой стороны, если вы настраиваете гиперпараметры на тестовом наборе данных, вы фактически используете тестовый набор данных в качестве обучающего. По этой причине точность, которую вы достигаете на нём, будет слишком оптимистичной по сравнению с тем, что будет наблюдаться на реальных данных при развёртывании модели. Но если вы используете тестовый набор данных только один раз в конце, он остаётся хорошим показателем для того, чтобы измерить степень обобщения вашего классификатора.
Итого: Оценивайте модель на тестовой выборке только один раз, в самом конце!
Существует правильный способ настройки гиперпараметров, который никак не затрагивает тестовый набор данных. Идея состоит в том, чтобы разделить обучающую выборку на две части: немного меньший обучающий набор и то, что называется выборкой для валидации. Используя в качестве примера CIFAR-10, мы могли бы использовать 49 000 обучающих изображений для обучения и оставить 1000 для валидации. Этот набор данных по сути используется для настройки гиперпараметров.
Вот как это может выглядеть в случае CIFAR-10:
# assume we have Xtr_rows, Ytr, Xte_rows, Yte as before # recall Xtr_rows is 50,000 x 3072 matrix Xval_rows = Xtr_rows[:1000, :] # take first 1000 for validation Yval = Ytr[:1000] Xtr_rows = Xtr_rows[1000:, :] # keep last 49,000 for train Ytr = Ytr[1000:] # find hyperparameters that work best on the validation set validation_accuracies = [] for k in [1, 3, 5, 10, 20, 50, 100]: # use a particular value of k and evaluation on validation data nn = NearestNeighbor() nn.train(Xtr_rows, Ytr) # here we assume a modified NearestNeighbor class that can take a k as input Yval_predict = nn.predict(Xval_rows, k = k) acc = np.mean(Yval_predict == Yval) print 'accuracy: %f' % (acc,) # keep track of what works on the validation set validation_accuracies.append((k, acc))
По завершении этой процедуры построим график, который показывает, какие значения k работают лучше всего. Затем мы остановимся на этом значении и проведем оценку на реальном тестовом наборе данных.
Разделите обучающую выборку на обучающую и валидационную. Используйте проверочную выборку для настройки всех гиперпараметров. В конце выполните один запуск на тестовой выборке и оцените производительность.
Кросс-валидация. В случаях, когда размер обучающих данных (и, следовательно, проверочных данных) может быть небольшим, люди иногда используют более сложный метод настройки гиперпараметров, называемый кросс-валидацией.
Если вернуться к нашему предыдущему примеру, то идея заключается в том, что вместо произвольного выбора первых 1000 точек данных в качестве проверочного набора, а остальных — в качестве обучающего, можно получить более точную и менее зашумлённую оценку того, насколько хорошо работает определённое значение k, перебирая различные проверочные наборы и усредняя результаты по ним. Например, при 5-кратной перекрёстной проверке мы разделили бы обучающие данные на 5 равных частей, использовали 4 из них для обучения, а 1 — для проверки. Затем мы бы определили, какая из выборок является контрольной, оценили бы производительность и, наконец, усреднили бы производительность по разным выборкам.
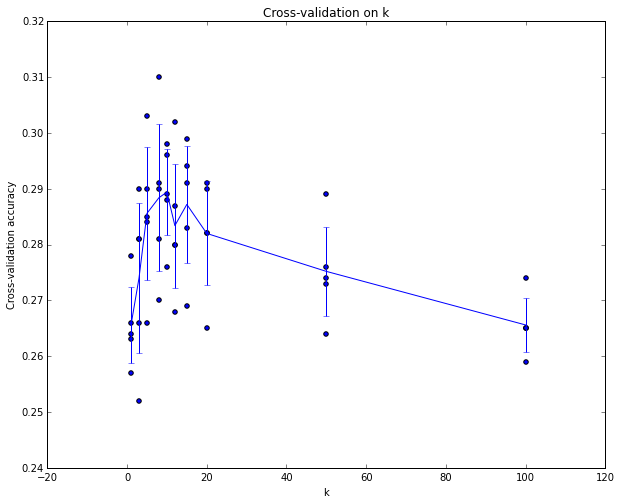
Пример 5-кратного выполнения перекрестной проверки для параметра k. Для каждого значения k мы тренируемся на 4 сгибах и оцениваем на 5-м. Следовательно, для каждого k мы получаем 5 значений точности для проверочного сгиба (точность отражается на оси y, и каждый результат равен точке). Линия тренда проводится через среднее значение результатов для каждого k, а столбики ошибок указывают на стандартное отклонение. Обратите внимание, что в данном конкретном случае перекрёстная проверка показывает, что значение около k = 7 лучше всего подходит для этого конкретного набора данных (соответствует пику на графике). Если бы мы использовали более 5 циклов, то могли бы ожидать более плавную (то есть менее шумную) кривую.
На практике люди предпочитают избегать перекрёстной проверки в пользу одного проверочного набора данных, поскольку перекрёстная проверка может быть ресурсозатратной. Обычно люди используют от 50% до 90% обучающих данных для обучения и остальную часть для проверки. Однако это зависит от множества факторов: например, если количество гиперпараметров велико, вы можете предпочесть использовать более крупные проверочные наборы данных. Если количество примеров в проверочном наборе невелико (возможно, всего несколько сотен или около того), безопаснее использовать перекрёстную проверку. На практике обычно используется 3-кратная, 5-кратная или 10-кратная перекрёстная проверка.

Обычное разделение данных. Выделяются обучающий и тестовый наборы данных. Обучающий набор данных делится на части (например, здесь их 5). Части 1-4 становятся обучающим набором данных. Одна часть (например, часть 5, выделенная здесь жёлтым цветом) называется проверочной частью и используется для настройки гиперпараметров. Перекрёстная проверка идёт дальше и позволяет выбрать, какая часть будет проверочной, отдельно от частей 1-5. Это называется 5-кратной перекрёстной проверкой. В самом конце, когда модель обучена и определены все наилучшие гиперпараметры, модель один раз оценивается на тестовых данных (красный цвет).
Плюсы и минусы классификатора ближайших соседей.
Стоит рассмотреть некоторые преимущества и недостатки классификатора «ближайший сосед». Очевидно, что одним из преимуществ является простота реализации и понимания. Кроме того, обучение классификатора не занимает много времени, поскольку всё, что требуется, — это хранить и, возможно, индексировать обучающие данные. Однако мы платим за это вычислительными затратами во время тестирования, поскольку для классификации тестового примера требуется сравнение с каждым обучающим примером. Это неправильно, поскольку на практике мы часто уделяем больше внимания эффективности во время тестирования, чем во время обучения. На самом деле, объемные нейронные сети, которые мы будем разрабатывать в этом классе, смещают этот компромисс в другую крайность: их обучение обходится очень дорого, но после завершения обучения классифицировать новый тестовый пример очень дёшево. Такой режим работы гораздо более желателен на практике.
Кроме того, вычислительная сложность классификатора «ближайший сосед» является активной областью исследований, и существует несколько алгоритмов и библиотек приблизительного поиска ближайшего соседа (ANN), которые могут ускорить поиск ближайшего соседа в наборе данных (например, FLANN ). Эти алгоритмы позволяют найти компромисс между точностью поиска ближайшего соседа и его пространственной/временной сложностью во время поиска и обычно полагаются на этап предварительной обработки/индексирования, который включает в себя построение KD-дерева или запуск алгоритма k-средних.
В некоторых случаях классификатор ближайших соседей может быть хорошим выбором (особенно если данные имеют низкую размерность), но он редко подходит для использования в практических задачах классификации изображений. Одна из проблем заключается в том, что изображения — это объекты с высокой размерностью (то есть они часто содержат много пикселей), а расстояния в многомерных пространствах могут быть очень нелогичными. На изображении ниже показано, что сходство на основе пикселей, которое мы описали выше, сильно отличается от сходства с точки зрения восприятия:

Расстояния на основе пикселей в многомерных данных (и особенно в изображениях) могут быть очень неинтуитивными. Исходное изображение (слева) и три других изображения рядом с ним, которые находятся на одинаковом расстоянии от него на основе пиксельного расстояния $L_2$. Очевидно, что пиксельное расстояние никак не соответствует перцептивному или семантическому сходству.
Вот ещё одна визуализация, которая убедит вас в том, что использование разницы в пикселях для сравнения изображений недостаточно. Мы можем использовать метод визуализации под названием t-SNE, чтобы взять изображения CIFAR-10 и разместить их в двух измерениях так, чтобы их парные (локальные) расстояния сохранялись наилучшим образом. В этой визуализации изображения, которые показаны рядом, считаются очень близкими в соответствии с расстоянием $L_2$ по пикселям, которое мы разработали выше:
![]()
Изображения CIFAR-10, размещённые в двух измерениях с помощью t-SNE. Изображения, расположенные рядом на этом изображении, считаются близкими на основе пиксельного расстояния $L_2$. Обратите внимание на сильное влияние фона, а не семантических различий между классами. Нажмите здесь, чтобы увидеть увеличенную версию этой визуализации.
В частности, обратите внимание, что изображения, расположенные друг рядом с другом, в большей степени зависят от общего цветового распределения изображений или типа фона, а не от их семантической идентичности. Например, собаку можно увидеть рядом с лягушкой, потому что они обе находятся на белом фоне. В идеале мы хотели бы, чтобы изображения всех 10 классов образовывали собственные кластеры, чтобы изображения одного класса находились рядом друг с другом независимо от нерелевантных характеристик и вариаций (например, фона). Однако, чтобы добиться этого, нам придётся выйти за рамки необработанных пикселей.
Применение kNN на практике
Подводя итог: - Мы рассмотрели задачу классификации изображений, в которой нам даётся набор изображений, каждое из которых помечено одной категорией. Затем нас просят предсказать эти категории для нового набора тестовых изображений и оценить точность прогнозов. - Мы представили простой классификатор под названием «классификатор ближайших соседей». Мы увидели, что существует множество гиперпараметров (например, значение k или тип расстояния, используемого для сравнения примеров), связанных с этим классификатором, и что не существует очевидного способа их выбора. - Мы увидели, что правильный способ задать эти гиперпараметры — разделить обучающие данные на две части: обучающий набор и поддельный тестовый набор, который мы называем набором для проверки. Мы пробуем разные значения гиперпараметров и оставляем те, которые обеспечивают наилучшую производительность на наборе для проверки. - Если вас беспокоит нехватка обучающих данных, мы обсудили процедуру под названием перекрёстная проверка, которая может помочь уменьшить погрешность при оценке наиболее эффективных гиперпараметров. - Как только мы находим оптимальные гиперпараметры, мы фиксируем их и проводим одну оценку на реальном тестовом наборе данных. - Мы увидели, что метод ближайшего соседа может обеспечить нам точность около 40% на CIFAR-10. Он прост в реализации, но требует хранения всего обучающего набора данных, и его сложно оценивать на тестовых изображениях. - В итоге мы увидели, что использование расстояний $L_1$ или $L_2$ по необработанным значениям пикселей нецелесообразно, поскольку эти расстояния сильнее коррелируют с фоном и цветовыми распределениями изображений, чем с их семантическим содержанием.
На следующих лекциях мы приступим к решению этих задач и в конечном итоге придём к решениям, которые обеспечат точность 90%, позволят полностью отказаться от обучающего набора данных после завершения обучения и позволят оценивать тестовые изображения менее чем за миллисекунду.
Если вы хотите применить kNN на практике (не на изображениях), действуйте следующим образом:
-
Предварительная обработка данных. Нормализуйте признаки в ваших данных (например, один пиксель на изображениях), чтобы среднее значение было равно нулю, а дисперсия — единице. Мы рассмотрим этот прием более подробно в следующих разделах. Сейчас нормализация данных не используется, потому что распределение яркости пикселей на изображениях достаточно однородны.
-
Рассмотрите возможность снижения размерности данных. На практике для снижения размерности используются следующие методы:
- метод главных компонент ссылка на вики-страницу, ссылка на CS229, ссылка на блог,
- метод независимых компонент ссылка на вики-страницу, ссылка на блог
-
Разделите обучающие данные случайным образом на обучающую и проверочную (валидационную) выборки. Как правило, в обучающую выборку попадает от 70 до 90% данных. Этот параметр зависит от того, сколько у вас гиперпараметров и насколько сильно они влияют на результат. Если нужно оценить множество гиперпараметров, лучше использовать более крупную проверочную выборку для их эффективной оценки. Если вас беспокоит размер проверочной выборки, лучше разделить обучающие данные на части и выполнить кросс-валидацию.
-
Обучите и оцените классификатор kNN на кросс-валидации. По возможности выполняйте кросс-валидацию для множества вариантов k и для разных типов расстояний ($L_1$ и $L_2$ — хорошие кандидаты).
Если вы можете позволить себе потратить больше времени на вычисления, всегда безопаснее использовать кросс-валидацию. Чем больше циклов обучения пройдет, тем лучше, но тем дороже с точки зрения вычислений. -
Оцените задержку классификатора. Если ваш классификатор kNN работает слишком долгo, рассмотрите возможность использования библиотеки приближённых ближайших соседей. Например, библиотека FLANN позволяет ускорить поиск за счёт некоторой потери точности.
-
Обратите внимание на гиперпараметры, которые дали наилучшие результаты. Возникает вопрос, следует ли использовать валидационный набор для финального обучения с наилучшими гиперпараметрами. Дело в том, что добавить данные для валидации в набор обучающих данных, оптимальные гиперпараметры могут измениться, поскольку размер данных увеличится. На практике лучше не использовать данные валидации в итоговом классификаторе и считать их потерянными при оценке гиперпараметров.
-
Оцените наилучшую модель на тестовом наборе данных. Вычислите точность на тестовой выборке и объявите результат производительностью классификатора kNN на ваших данных.
Дополнительные материалы
Вот несколько дополнительных ссылок, которые могут быть интересными для дальнейшего чтения:
- Несколько полезных фактов о машинном обучении, особенно раздел 6, но рекомендуется к прочтению вся статья.
- Распознавание и изучение категорий объектов, краткий курс по категоризации объектов на ICCV 2005.













{kind=link}